学院新闻
College News

近日,9728太阳集团金琴教授团队AIM3多媒体计算实验室2篇长文《MM-Diffusion: Learning Multi-Modal Diffusion Models for Joint Audio and Video Generation》《Open-Category Human-Object Interaction Pre-training via Language Modeling Framework》被计算机视觉和模式识别领域顶会CVPR录用。CVPR(Computer Vision and Pattern Recognition,计算机视觉与模式识别)会议是计算机视觉与模式识别、人工智能领域的国际顶级会议,是中国计算机学会(CCF)推荐的A类国际学术会议。本届会议录用率为25.78%。
2篇论文的第一作者分别是来自AIM3多媒体计算实验室的2020级硕士生阮璐丹、2018级博士生郑思鹏。
论文题目:MM-Diffusion: Learning Multi-Modal Diffusion Models for Joint Audio and Video Generation
作者:阮璐丹,马逸扬(北京大学),杨欢(微软),何汇国(微软),刘蓓(微软),傅建龙(微软),Nicholas Jing Yuan(微软),金琴,郭百宁(微软)
论文概述:
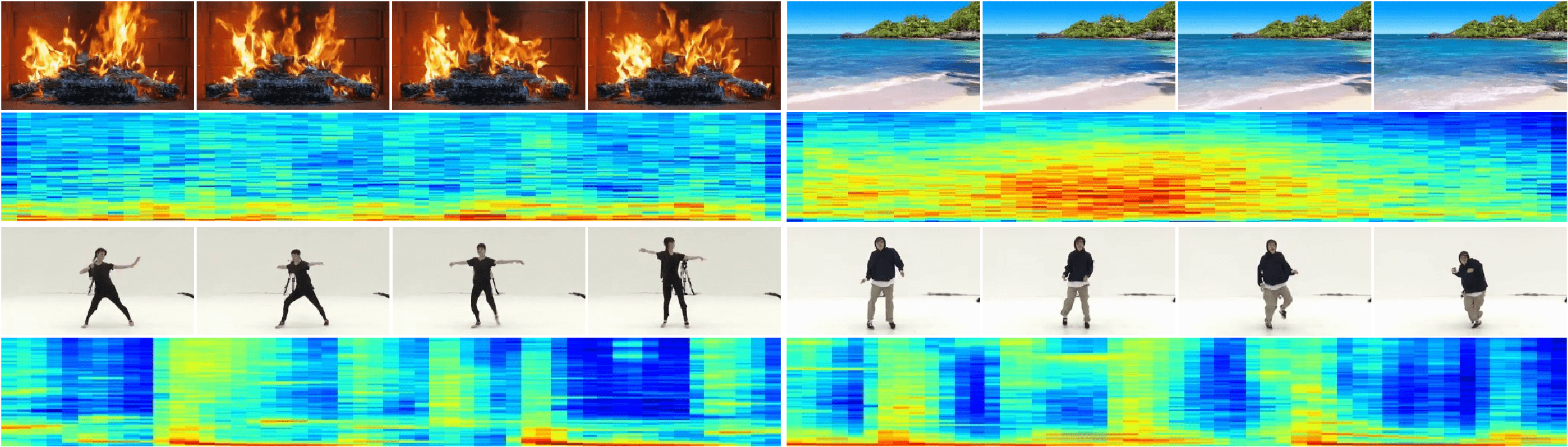
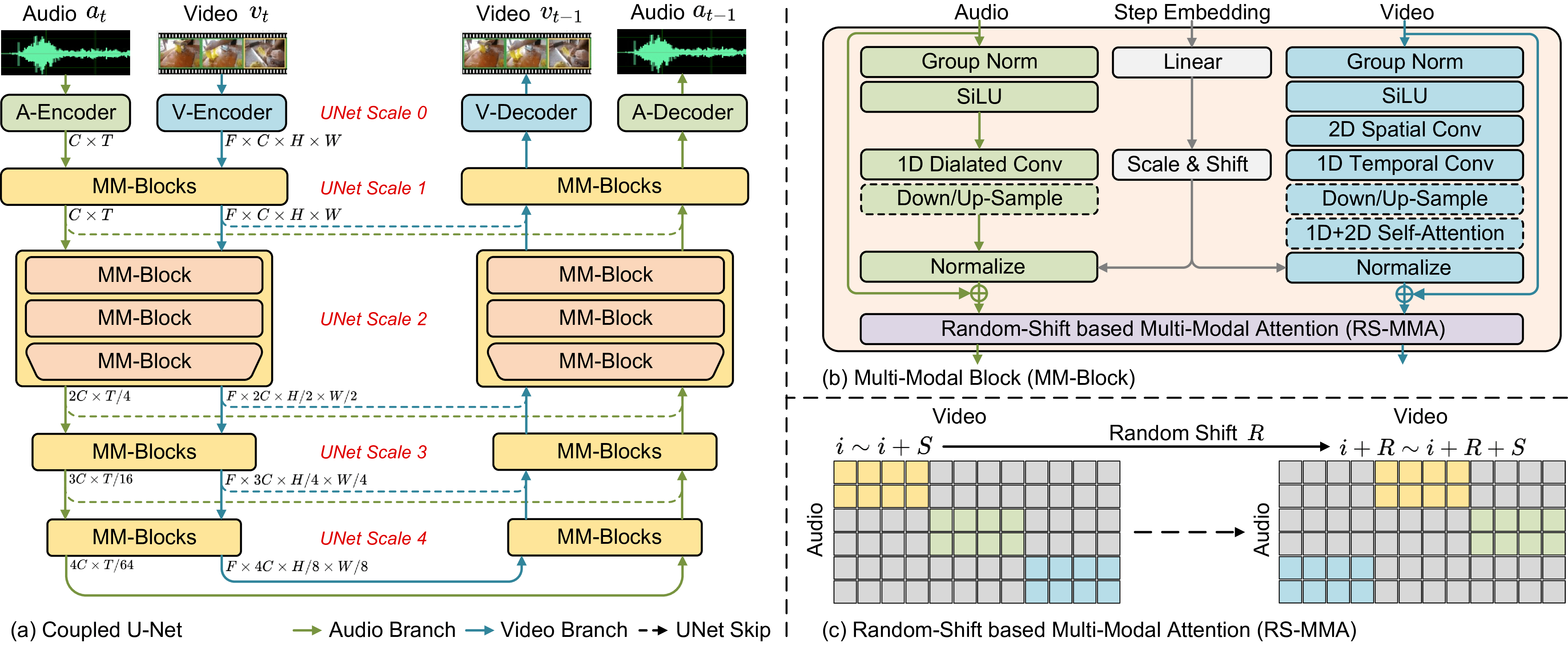
基于AI的智能创作已经在不同子领域得到了令人瞩目的成绩(图像生成、视频生成、音频生成),但是目前的工作主要聚焦在单模态内容生成上,考虑到不同模态间天然存在着对齐关系,本文提出了首个音-视频对生成模型Multi-Modal Diffusion (MM-Diffusion)。该模型由两支相对独立的U形子网络构成,一支用于视频建模、一支用于音频建模。为了高效建模音视频之间的时序对应关系,我们提出了基于随机偏移的Attention模块去桥接两个子网络。实验显示对比单模态生成,两个模态同时生成质量会更高。除此之外,我们的模型具备zero-shot 条件生成的能力(输入视频生成对应音频或反之)。我们为这个任务构建了Landscape数据集,并在客观指标、人工评测等角度在Landscape、AIST++两个数据集上衡量,实验结果均超过了之前可复现单模态生成的SOTA。
论文题目:Open-Category Human-Object Interaction Pre-training via Language Modeling Framework
作者:郑思鹏,许博深,金琴
通讯作者:金琴
论文概述:
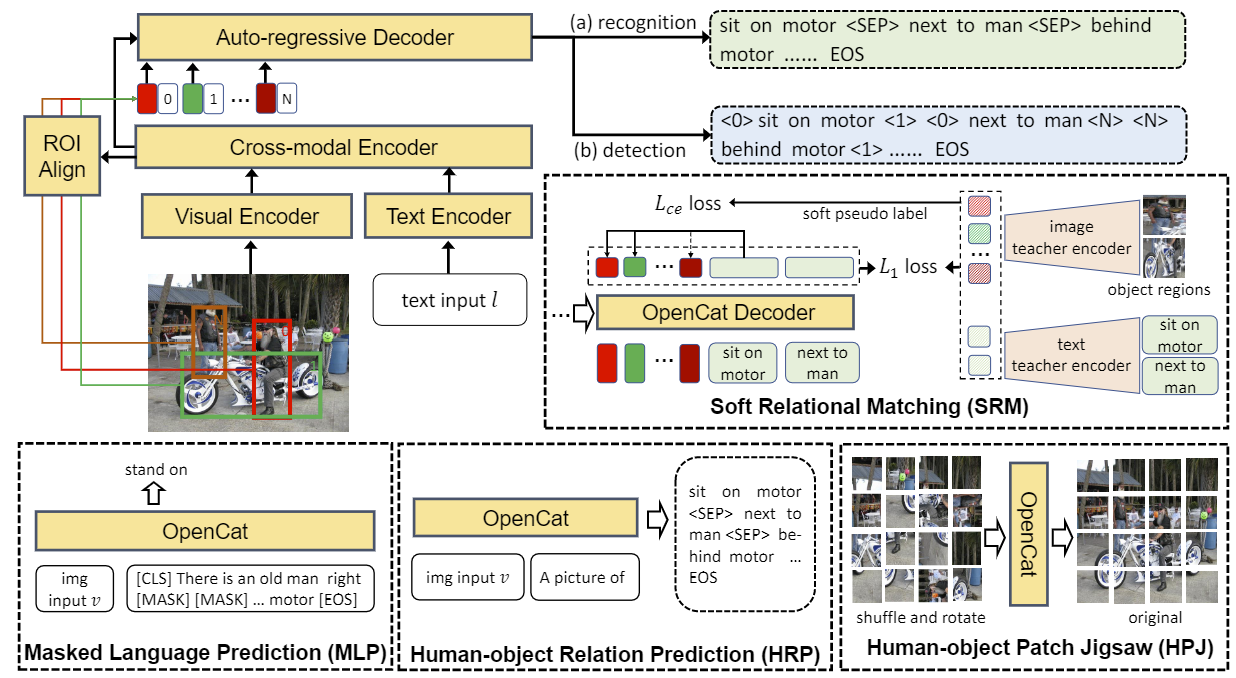
在现实生活中,有限的监督数据和海量交互组合之间的矛盾一直困扰着人-物交互检测任务(HOI)。当前的工作大多基于封闭类别集合数据训练得到,它们将HOI学习视为一个预先定义好类别词典的分类任务,利用一个分类器将输入图像映射成维度固定的logits,因此难以将这些方法扩展到新类别上。为了解决这个问题,我们提出了一个名为OpenCat的语言建模框架,它将预测HOI实例的过程重构为一个序列生成任务,通过采用序列化方案将每一个HOI三元组转换为令牌序列。按照这种做法,OpenCat能够利用语言建模框架具有开放集合词汇表的特点,以极高的自由度预测新的交互类别。此外,受到当前已有的视觉语言预训练模型的启发,我们从图像字幕对这样的数据中收集了大量弱标签,并提出了几个代理任务,包括掩码语言预测、人-物象关系预测、软关系匹配等等,用来辅助模型的预训练过程。大量实验表明,我们提出的OpenCat模型在数个HOI相关的评测数据集上都获得了显著的性能提升,尤其是在少样本和未见类别上。
作者简介:
阮璐丹,9728太阳集团2020级硕士,计算机应用技术专业,主要研究方向是多模态预训练,多模态生成等。

郑思鹏,9728太阳集团2018级博士,计算机应用技术专业,主要研究方向是视频关系和行为理解,多模态等

金琴,中国9728太阳集团计算机系教授,多媒体计算实验室(AIM3)负责人。主要研究领域为多媒体智能计算、人机交互。

Copyright © 2015 School of Information, Renmin University of China. All rights reserved.
版权所有 太阳成集团tyc9728(股份)有限公司-官方网站