学院新闻
College News

标题:FC-KBQA: A Fine-to-Coarse Composition Framework for Knowledge Base Question Answering
第一作者:张灵溪
通讯作者:张静
录用会议:ACL 2023
摘要:
KBQA的泛化问题已经引起了广泛的关注。现有的研究普遍对逻辑查询表达式(例如SPARQL)进行粗粒度建模,导致逻辑表达式中的知识表征耦合在一起,从而带来泛化问题。本文提出了一个从细粒度到粗粒度建模的KBQA框架FC- KBQA,在确保逻辑表达式泛化能力的同时保证可执行性。FC-KBQA的主要思想是,从知识库中提取相关的细粒度知识成分,并将其按照KB约束组合为连通的中粒度知识对,最后用生成模型生成最终的逻辑表达式。FC-KBQA在GrailQA和WebQSP上获得了较好的表现,同时也保证了较快的运行速度。
研究动机:
知识库问题回答(KBQA)旨在提供一种用户友好的方式,通过自然语言访问大规模的知识库(KB)。为了回答复杂的自然语言问题,一种KBQA方法基于语义分析(SP-based KBQA),并在i.i.d.数据集上取得了较好的结果。这种基于SP的方法首先将问题翻译成逻辑表达式,如SPARQL,然后在KB上执行这些表达式以得到最终答案。然而,大部分SP-based KBQA存在泛化问题,即当逻辑表达式中包含训练集中没有出现的知识时准确率较低。我们认为,泛化问题主要是由于现有方法在建模时将逻辑表达式看作是不可分割的单元。但实际上,逻辑表达式是粗粒度的,可以被分解成相对细粒度的知识成分,包括关系、类、实体和逻辑骨架,如下图所示。
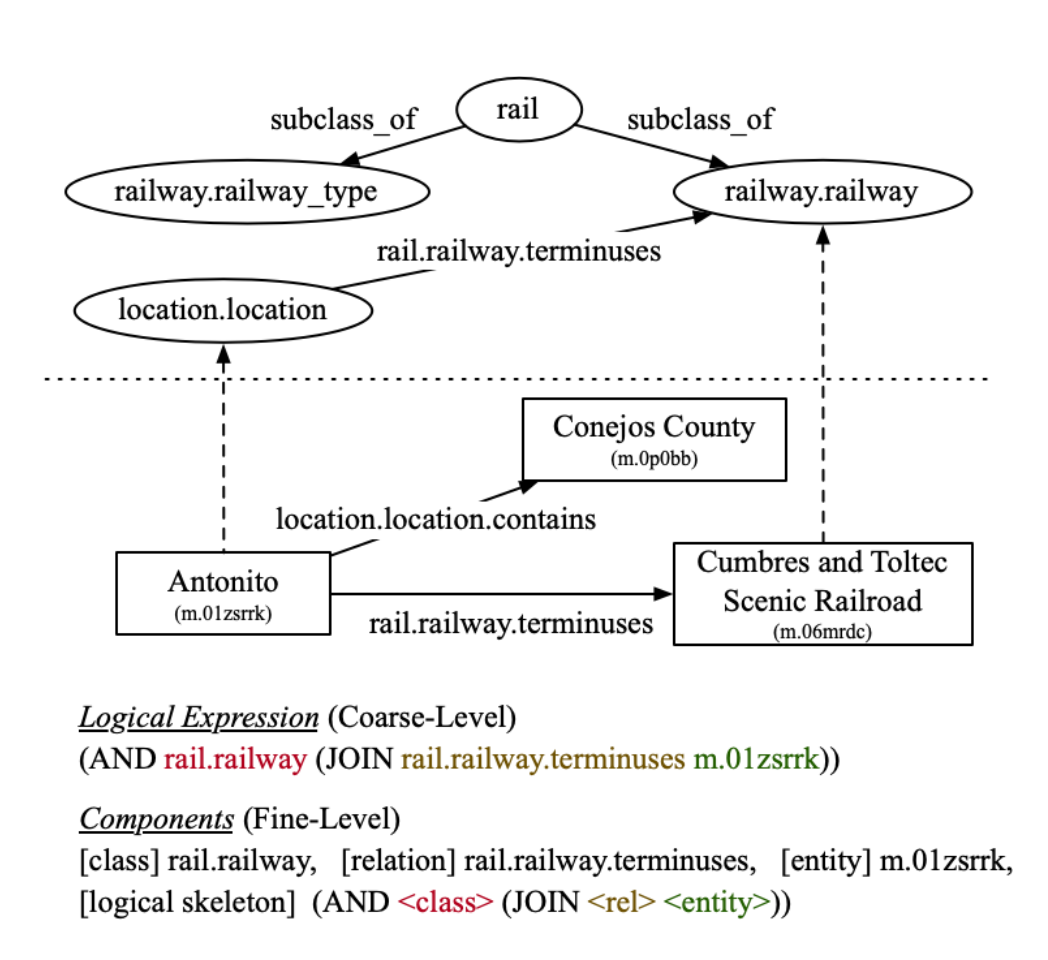
这种粗粒度的建模使细粒度知识的表征纠缠在一起,导致训练过程中模型对知识成分的组合过度拟合,削弱了模型的泛化能力,同时降低了对细粒度成分的零样本泛化能力。
解决方案:
我们首先通过一个预实验证明细粒度的建模(先将问题和逻辑表达式中的每个知识元素匹配然后选取得分最高的知识元素组成最终的逻辑表达式)优于粗粒度的建模(直接将逻辑表达式和问题匹配打分),并根据这个结论设计了主要框架。具体来说,如下图,
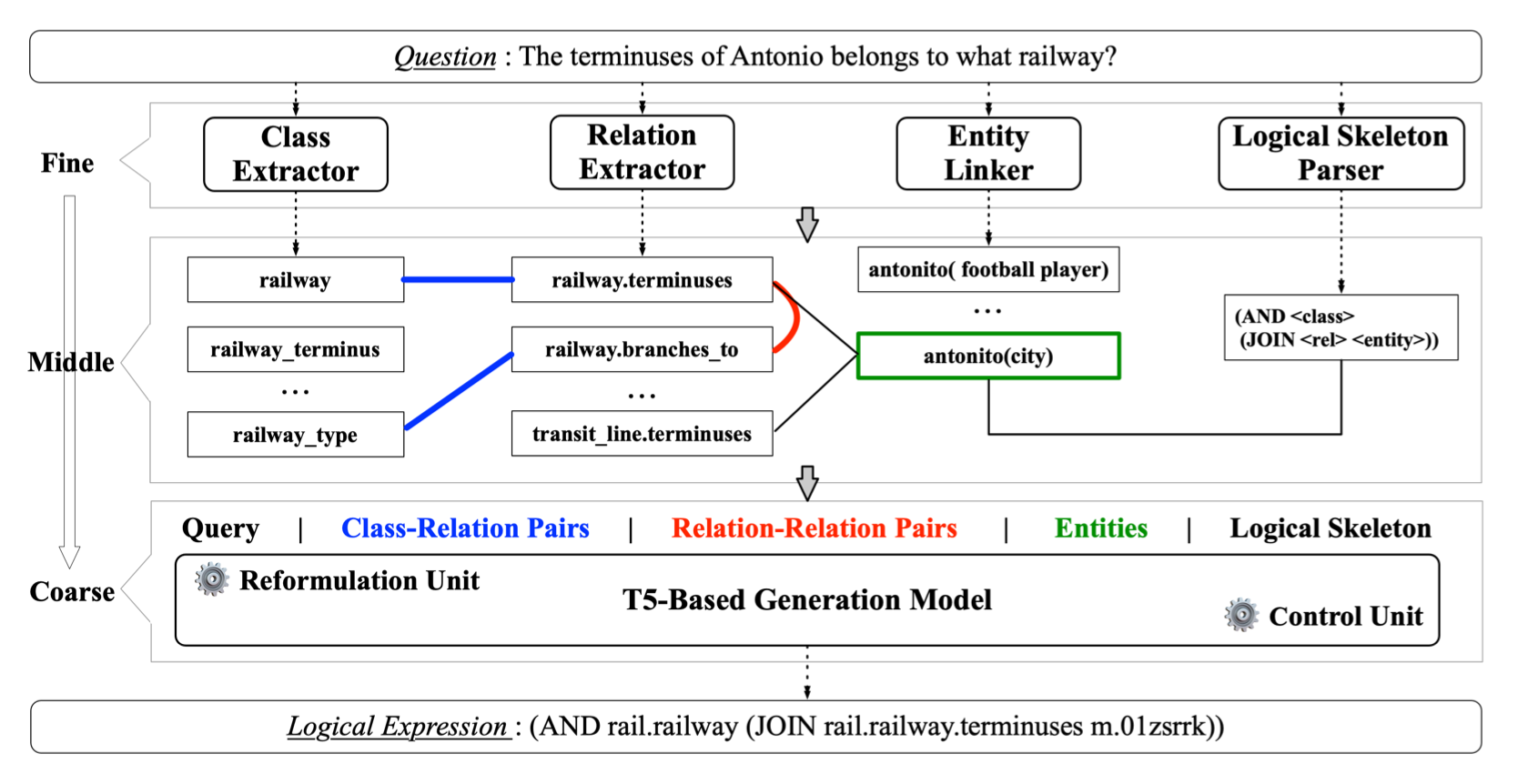
第一个模块是细粒度的知识元素探测模块,根据细粒度元素和问题的语义相似性从Freebase中检测各种细粒度的候选。这样的探测保证了泛化能力。第二个模块是中粒度的元素约束,根据元素在知识库中的连接性来有效地修剪和组合细粒度的元素候选,从而保证连通性。最后一个模块是粗粒度元素组合,采用了一个序列到序列的生成模型来生成可执行的粗粒度逻辑表达式,生成模型的输入是细粒度的元素以及中粒度的元素对,输出是经过KB字典约束的可执行逻辑表达式。与之前的工作相比,我们强调中粒度的元素对,在保证泛化性的同时保证生成逻辑表达式的连通性。
我们的模型在泛化数据集GrailQA以及i.i.d.数据集WebQSP, CWQ上都取得了较优的效果。
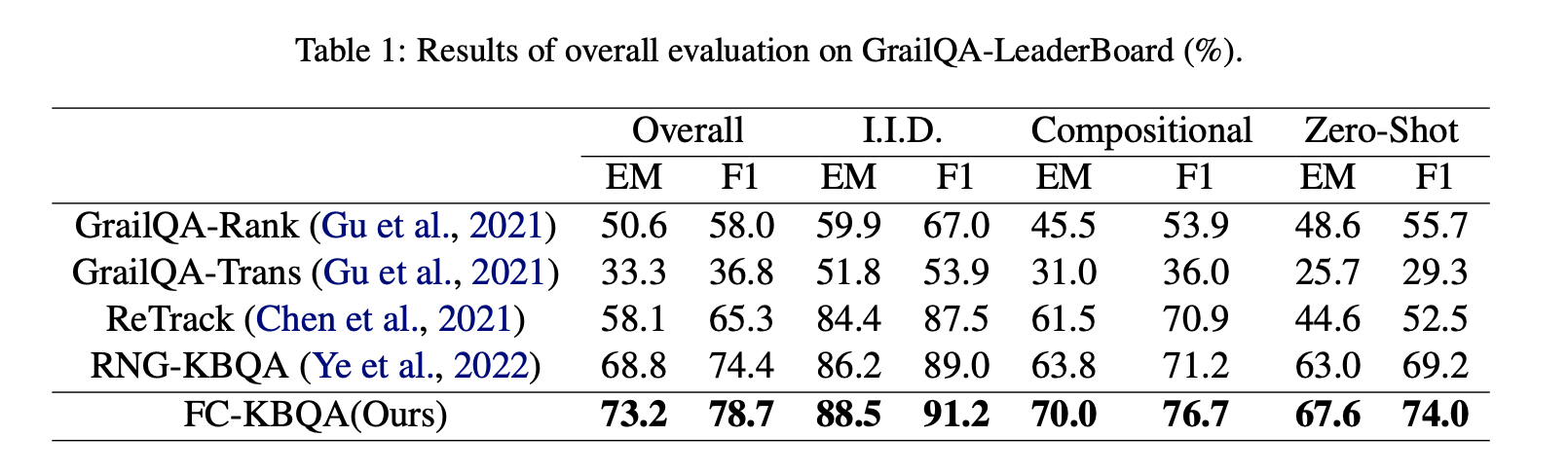
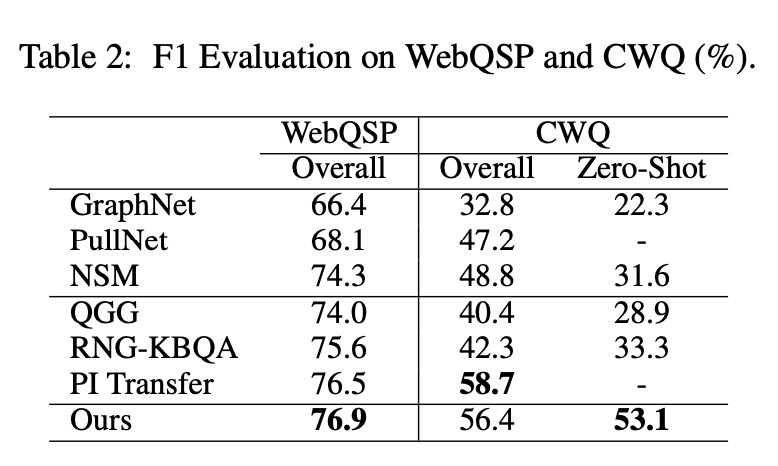
作者简介:
张灵溪,9728太阳集团2021级硕士生,计算机应用技术专业。目前主要研究方向是知识推理以及自然语言处理。

张静,9728太阳集团计算机系副教授。目前主要研究方向是知识图谱融合与推理等方面的相关研究。发表论文60余篇,其中包括十余篇KDD、SIGIR、WWW、ACL、TKDE、TOIS、IJCAI、AAAI、CIKM、WSDM等国际顶级会议或期刊论文。Google引用次数7000余次。近年来任WWW、IJCAI、PKDD/ECML等领域内国际顶级学术会议高级程序委员会委员以及TKDE、中国科学等知名杂志审稿人。任IEEE TBD以及AI Open期刊Associate Editor。

Copyright © 2015 School of Information, Renmin University of China. All rights reserved.
版权所有 太阳成集团tyc9728(股份)有限公司-官方网站