学院新闻
College News

近日,9728太阳集团金琴教授团队AIM3多媒体计算实验室论文VRDFormer: End-to-End Video Visual Relation Detection with Transformers被计算机视觉和模式识别领域顶会CVPR录用。CVPR(Computer Vision and Pattern Recognition, 计算机视觉与模式识别 )会议是计算机视觉与模式识别、人工智能领域的国际顶级会议,影响因子在泛AI领域排名第一。

录用论文题目为“VRDFormer: End-to-End Video Visual Relation Detection with Transformers”,第一作者是9728太阳集团2018级直博生郑思鹏,导师为金琴教授,本科毕业于9728太阳集团,主要研究计算机视觉方向的关系检测和动作识别等任务。第二作者为9728太阳集团2020届博士毕业生陈师哲,通讯作者为金琴教授。论文提出了一个端到端的基于transformer的模型用来解决现有视频关系检测任务多个模块无法共同训练以及候选关系对过多的问题,在主要的数据集上均有了很大的提升。

我们通常用 <主体,动作,客体> 这种三元组的形式来表示日常生活中物体对之间的关系,比如 <人,骑,马> 这样的动作,由此产生了“视频关系检测”这样一个视觉任务,它要求模型检测出一个视频里每一对关系所属物体和动作类别,以及它在时间和空间上的位置。该任务能够帮助机器更好地理解视频的场景内容。
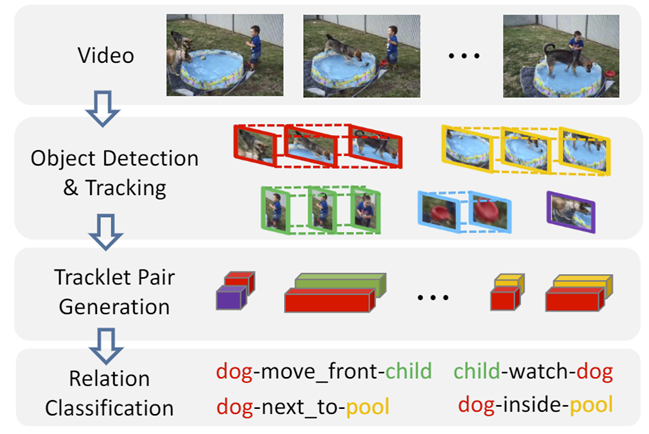
传统的视频关系检测工作遵循着一种多阶段的系统框架,如图所示,整个检测系统分为目标检测,目标追踪,关系对配对以及关系分类等不同模块,存在着以下几个缺陷影响模型表现:(1)不同阶段的模块都是单独训练的,彼此之间互不关联;(2)该框架需要穷尽视频内所有可能的关系候选组合。
本文提出了一个端到端的模型去解决第一个问题,同时我们注意到基于query-based transformer的方法已经在图像关系任务上解决了候选对过多的问题,本文沿用了这一思路旨在解决第二个问题。
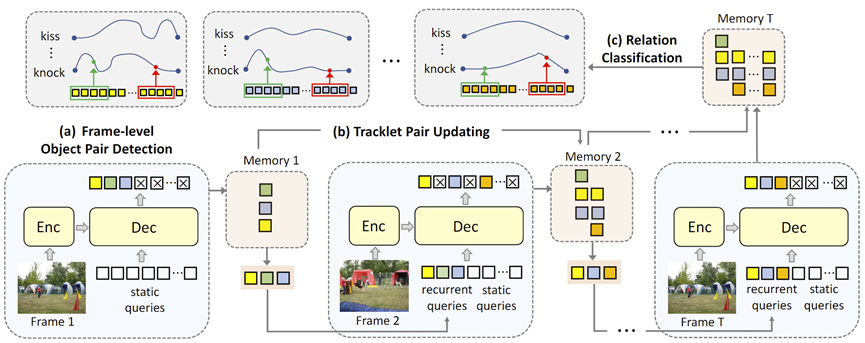
首先我们只研究视频里单帧的情景。对于视频里的每一帧,一个在不同帧之间共享参数的编码解码器把帧图像作为输入,同时解码器一端有若干个query与编码器的输出作为解码器的输入。每一个query都是一个可学习的向量,它会对应到当前帧里某一个关系对,负责该关系对的位置输出和类别预测。类似地,我们对每一帧都做了这样的预测,于是我们可以得到视频里每一帧的关系情况。
对于多帧视频,我们将不同帧的物体关系在时序上进行串联,可以得到时序上的轨迹关系对变化情况,这一过程与目标跟踪相仿。为了限制query处理的数量,我们受启发于trackformer工作,将query分成两个部分:固定数量的static query用于单帧的物体关系对检测,然后我们根据阈值筛选出我们觉得比较可能存在关系的query,作为recurrent query送到下一帧,和下一帧的static query一起作为解码器的输入,整个过程是自回归的,如上图所示。通过限制recurrent query的数量,我们每次要处理的query数就显著下降了。同时,在自回归迭代的过程中,筛选出的query vector会被作为轨迹关系对的memory进行保存,在对整个视频检测完毕之后我们再用这些memory进行关系分类。
经过了上面的自回归迭代,我们检测出了视频里所有可能存在关系的物体对,知道了它们在时间和空间上的位置。接着,我们对每一个轨迹关系对,用一个transformer去编码它的memory信息,以此来得到它在时序上的长距离依赖关系,最后利用这个transformer的输出进行关系预测,这样我们就知道了这个轨迹关系对在视频里的每一帧的关系分类。
我们的训练分为两个部分,第一个部分用二分匹配的方法进行优化,这部分内容与DETR相仿,主要的目的就是希望我们的query能够具有分类和定位物体关系对的能力;第二部分我们直接用标注的轨迹关系对初始化视频里每一帧的query,在得到每一个轨迹关系对的memory之后做分类预测,这部分主要优化关系分类的transformer模块,目的是希望模型能够具有编码长时memory的能力。
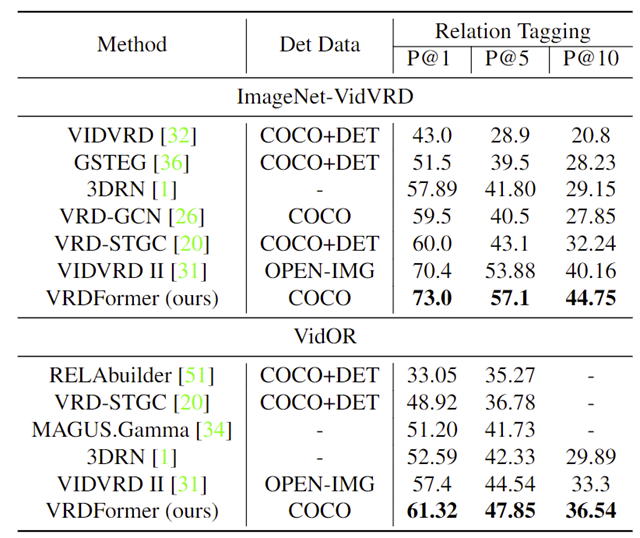
我们在该任务两个传统的数据集VidVRD和VidOR上分别做了relation tagging和relation detection两个子任务的实验,并都取得了最佳效果。

Copyright © 2015 School of Information, Renmin University of China. All rights reserved.
版权所有 太阳成集团tyc9728(股份)有限公司-官方网站