学院新闻
College News

近日第45届国际计算机学会信息检索大会(The 45th International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR 2022)接收结果公布,金琴教授团队AIM3多媒体计算实验室1篇长文被录用。SIGIR 2022是人工智能领域智能信息检索方向的顶级国际会议,CCF A类推荐会议。
本文题目为Progressive Learning for Image Retrieval with Hybrid-Modality Queries,第一作者是9728太阳集团2019级硕士生赵一达,导师为金琴教授。主要研究方向为视觉和语言、多模态检索。

复合模态查询的图片检索,也称为组合文本和图片的图片检索(Composing Text and Image for Image Retrieval, CTI-IR),是以包含视觉和文本两个模态的复杂查询格式表达搜索意图的一项检索任务。例如,将一张参考图片和修改该图片的文本作为联合查询输入来检索目标图片。这是一项更具挑战性的图片检索任务,本文总结该任务主要有以下三点挑战:1) 模型既要学习用于目标图片检索的联合语义空间,又要学习复合模态查询输入的多模态融合;2) 该任务主要关注于时尚领域,特定领域的<参考图片,>三元组训练数据十分稀缺;3) 复合模态查询中的每个模态的重要程度在不同的检索场景下是不同的。
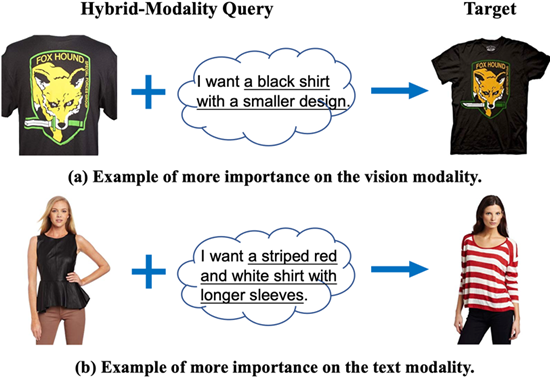
本文提出了一种多阶段渐进学习的策略,将CTI-IR任务分解为一个三阶段学习问题,让模型逐步学习用于图片检索的复杂知识。在阶段一首先利用CLIP在公开领域的图片文本检索能力对模型的编码器进行初始化,在阶段二通过与时尚相关的两个预训练任务将学习到的知识迁移至时尚领域,包括时尚图片检索任务和时尚属性预测任务。最后,在阶段三针对CTI-IR任务,引入复合模态查询输入融合模块,将模型从单一查询拓展为复合模态查询。由于在不同的检索场景下复合模态查询中各个模态的重要程度不同,本文提出了一种自监督自适应加权策略来动态确定图片和文本在复合模态查询中的重要性,以达到更好的检索效果。实验结果表明,本文模型在Fashion-IQ和Shoes两个公开数据集上都取得了最佳结果。
Copyright © 2015 School of Information, Renmin University of China. All rights reserved.
版权所有 太阳成集团tyc9728(股份)有限公司-官方网站