学院新闻
College News

会议介绍:

ACM 国际多媒体会议(ACM International Conference on Multimedia)是计算机科学多媒体领域的首要国际会议。今年ACM MM收到的投稿数创造历史新高。金琴教授AIM³实验室的三篇长文论文被会议接收。由于疫情影响,本次会议完全采取线上的形式。

(由于疫情影响,ACM MM完全采取线上的会议的形式进行。)
论文介绍
1、VideoIC: A Video Interactive Comments Dataset and Multimodal Multitask Learning for Comments Generation
作者:王维莹(硕士),陈洁婷(硕士),金琴

作为新兴的交互式媒体,弹幕深受年轻观众的欢迎。与一般的视频评论不同,每条弹幕与特定的视频时刻相关。此外,它还具有两个显著的交互特性:多媒体交互性和用户交互行。为了进一步了解弹幕的独特特性,本文选择弹幕生成任务进行探索。本文根据弹幕的特性,设计了一个基于多模态多任务学习的模型。该模型首先可以利用包括文本,视觉和音频多个模态的信息。其次,该模型引入了时序关系预测,帮助模型编码不同模态的信息的语义关系和时序关系,协助弹幕生成任务。为支持弹幕相关研究,本文还建立了一个包含高密度弹幕的视频数据集VideoIC。模型在之前的公开低弹幕密度数据集Livebot和高密度数据集VideoIC上均取得了最佳结果。论文还对不同模态信息的使用和交互方式对生成结果的影响进行了探索。
2、ICECAP: Information Concentrated Entity-aware Image Captioning
作者:胡安文(博士),陈师哲(博士),金琴
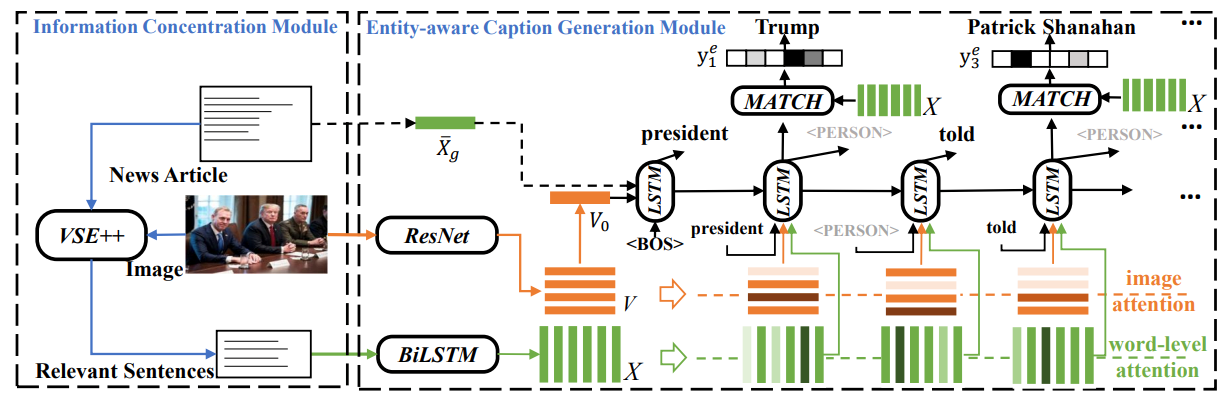
大部分现有的图像描述模型都关注于描述照片上的对象。它们缺乏背景知识去充分地理解图片,比如图片上人物的姓名或者与图片相关的事件。这篇工作关注为新闻图片产生包含命名实体的自然语言描述。在这类任务中,我们可以借助新闻图片附属的新闻文章来提供相关的背景知识。受限于新闻文章的较长的文本长度,先前的工作只能在比较粗的粒度上利用新闻文章,比如在整个文章层面或者句子层面。这对于提取关键事件,生成正确的命名实体都是不够精确的。为此,我们提出了一个名为ICECAP的模型。该模型从句子层面到词语层面逐步地从新闻文章中抽取出相关信息。模型首先用一个多模态检索模型抽取与图片最相关的句子,然后在词语级别利用这些句子生成图像描述。我们的模型在BreakingNews和GoodNews两个数据集上都取得了最好的结果。
3、Semi-supervised Multi-modal Emotion Recognition with Cross-Modal Distribution Matching
作者:梁景俊(硕士)、李瑞晨(硕士),金琴
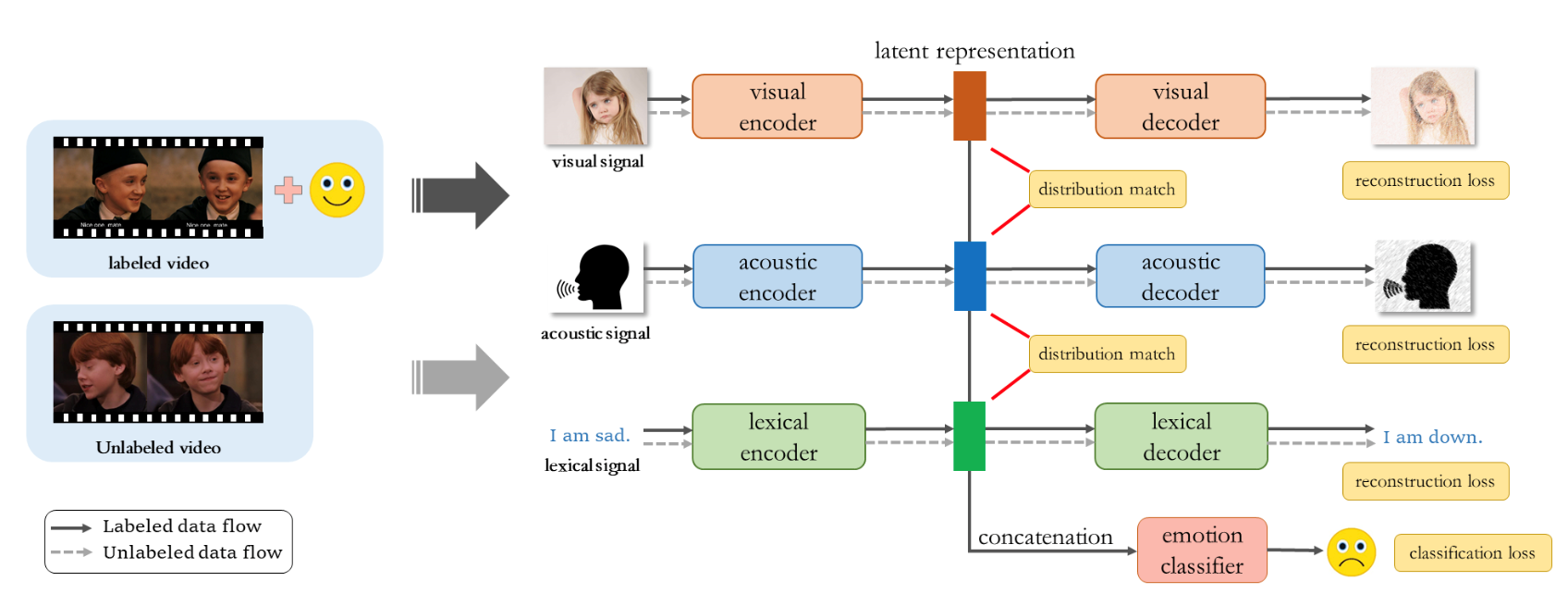
自动情感识别是一项具有广泛的应用的研究。由于高昂的人工标注成本和不可避免的标注模糊性,情感识别数据集的发展在规模和质量上都受到限制。因此,该领域的关键挑战之一是如何在有限的数据资源下建立有效的模型。先前的工作已经探索了解决此问题的不同方法,包括数据增强,传输学习和半监督学习等。但是,这些现有方法具有许多弱点,包括训练不稳定,迁移过程中出现的大量性能损失问题等。
针对以上问题,我们提出了一种基于跨模态分布匹配的半监督多模态情感识别模型,基于多模态特征在句子级别的情感表达一致的假设,利用大量未标记数据来增强模型训练。我们在两个数据集IEMOCAP和MELD上评估了我们提出的模型。实验结果表明,我们提出的半监督学习模型可以有效地利用未标记的数据,并结合多模态信息来提高情感识别性能。
Copyright © 2015 School of Information, Renmin University of China. All rights reserved.
版权所有 太阳成集团tyc9728(股份)有限公司-官方网站